Vision-language-action (VLA) models increasingly rely on diverse training data to achieve robust generalization.
However, collecting large-scale real-world robot manipulation data across varied object appearances and environmental conditions
remains prohibitively time-consuming and expensive. To overcome this bottleneck, we propose Embodied Manipulation Media Adaptation (EMMA),
a VLA policy enhancement framework that integrates a generative data engine with an effective training pipeline.
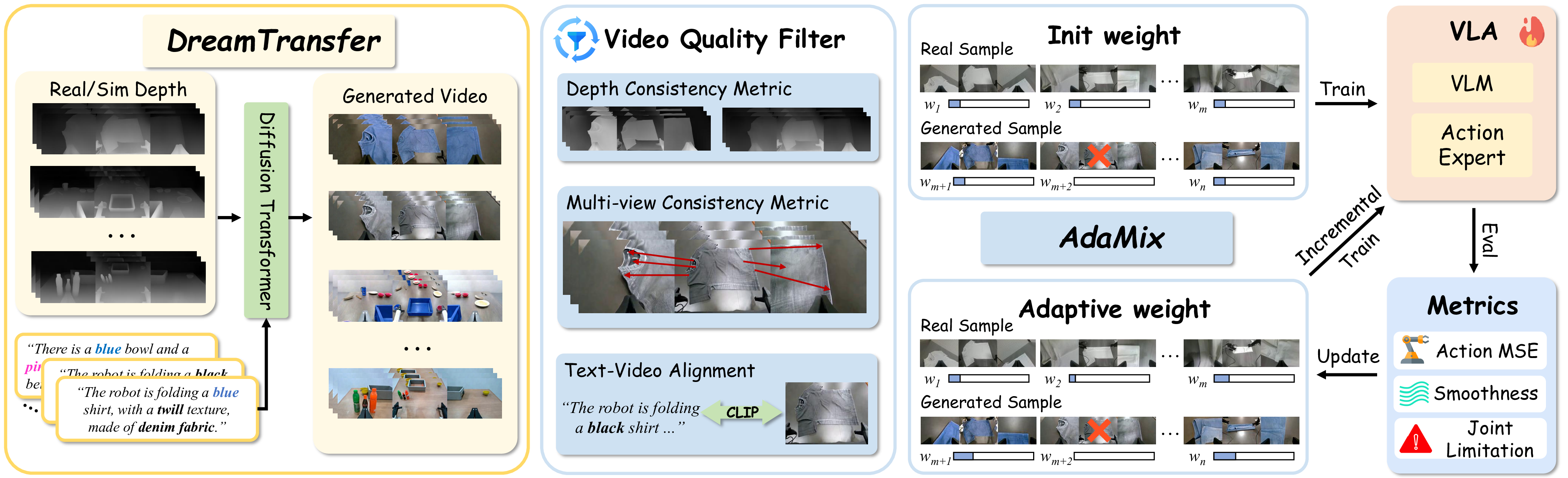
We introduce DreamTransfer, a diffusion Transformer-based framework for generating multi-view consistent,
geometrically grounded embodied manipulation videos. DreamTransfer enables text-controlled visual editing of robot videos,
transforming foreground, background, and lighting conditions without compromising 3D structure or geometrical plausibility.
Furthermore, we explore hybrid training with real and generated data, and introduce AdaMix, a hard-sample-aware training
strategy that dynamically reweights training batches to focus optimization on perceptually or kinematically challenging samples.
Extensive experiments show that videos generated by DreamTransfer significantly outperform prior video generation methods
in multi-view consistency, geometric fidelity, and text-conditioning accuracy. Crucially, VLAs trained with generated data enable
robots to generalize to unseen object categories and novel visual domains using only demonstrations from a single appearance.
In real-world robotic manipulation tasks with zero-shot visual domains, our approach achieves over a 200% relative performance
gain compared to training on real data alone, and further improves by 13% with AdaMix, demonstrating its effectiveness in boosting
policy generalization.